Actions and the Dispatcher
이 가이드는 원래 React 블로그에 게시된 포스트며 편집 후 여기에 추가되었다.
The Dispatcher #
Dispatcher는 싱글턴으로 Flux 어플리케이션의 데이터 흐름을 담당하는 중앙 허브와 같이 동작한다. 이는 본질적으로 콜백을 등록하고 등록된 콜백을 순서에 따라 실행할 수 있다. 각각의 store는 dispatcher에 콜백을 등록한다. 새로운 데이터가 dispatcher에 오게 되면 이 콜백은 데이터를 모든 store에 전파하기 위해 등록된 모든 콜백을 사용한다. 콜백을 실행하는 과정은 dispatch() 메소드를 통해 시작하고 데이터 페이로드 객체를 단일 인수로 포함한다. 이 페이로드는 일반적으로 action와 동의어로 사용된다.
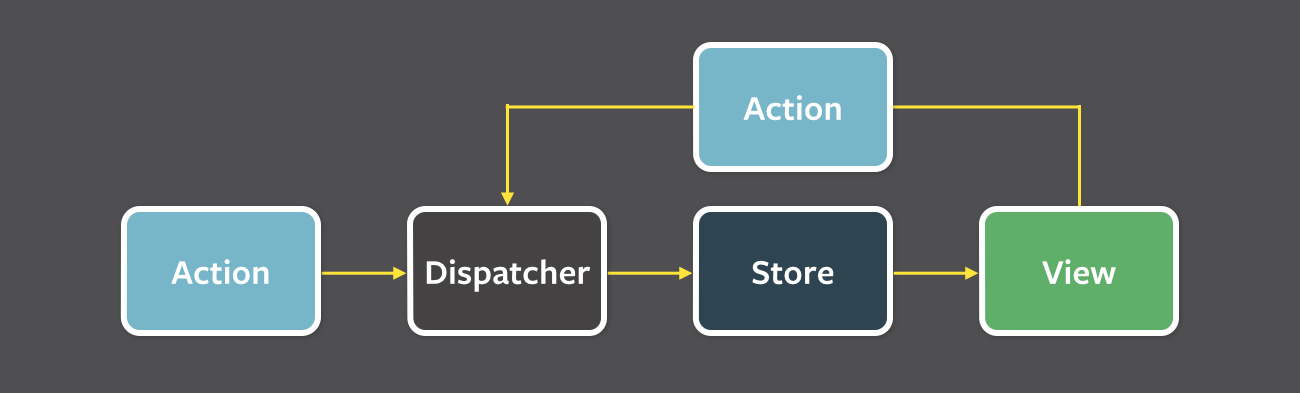
Actions and Action Creators #
사용자의 어플리케이션 조작이나 웹 API의 호출 등으로 새로운 데이터가 시스템에 들어오면 데이터는 새로운 데이터와 특정 action type을 담아 action으로 묶는다. 종종 action creators라는 이름으로 헬퍼 메소드를 만드는데 action 객체를 만드는 것 뿐 아니라 action을 dispatcher로 보낼 때에도 사용한다.
각 action의 차이는 type 어트리뷰트로 구분한다. 모든 store가 action을 받을 때는 이 어트리뷰트를 이용해 store에서 응답을 해야 하는가를 결정한다. Flux 어플리케이션에서는 store와 view 모두 스스로를 조작한다. 즉 외부의 객체에 의해 행동하지 않는다. action이 store로 전달될 때는 setter 메소드를 사용하는 것이 아니라 store가 미리 등록했던 콜백을 통해 store로 흘러 들어간다.
store가 그 스스로 갱신되도록 하는 것은 MVC 어플리케이션에서 쉽게 찾을 수 있는 많은 혼란을 줄여준다. 모델 간에 연쇄적으로 갱신된다면 상태가 불안정하게 되고 정밀한 테스트가 매우 어렵다. Flux 어플리케이션의 객체는 고도로 결합도를 낮췄고 디미터의 법칙을 강하게 따르고 있다. 이 법칙은 시스템에 포함된 각각의 객체가 시스템에 있는 다른 객체를 가능한 한 서로 적게 알도록 만들라는 뜻이다. 이 결과로 소프트웨어는 더 관리 가능하고, 유연하고, 테스트 가능하며, 새로운 엔지니어링 팀 구성원도 쉽게 이해할 수 있게 된다.
왜 Dispatcher가 필요할까 #
어플리케이션의 규모가 커지면 여러 store 간의 의존성이 생기는 것은 불가피한 일이다. Store A는 꼭 Store B가 먼저 갱신되야 자신을 어떻게 갱신하는지 알 수 있다. dispatcher는 Store A의 콜백보다 Store B의 콜백을 먼저 실행할 수 있다. 의존성을 명확하게 선언하는 것으로 "나는 Store B이 이 행동을 처리하는 것이 끝날 때까지 기다릴 것이다" 라고 store가 dispatcher에게 이야기 할 필요가 있다. dispatcher는 이 기능을 waitFor() 메소드를 통해 제공한다.
dispatch() 메소드는 단순하게 동기적으로 반복해서 모든 콜백을 실행하는 방식으로 제공된다. waitFor() 메소드가 한 콜백을 만나게 되면 콜백의 실행은 잠시 중단되고 waitFor()는 의존성을 넘어 새로운 반복 사이클을 제공한다. 그리고 나서 모든 의존성이 실행이 되면 원래의 콜백으로 돌아와 실행을 계속 진행한다.
나아가, waitFor() 메소드는 같은 store의 콜백 내에서도 다른 action에 다른 방법으로 사용할 수 있다. 예를 들면 어떤 상황에서는 Store A가 Store B를 필요로 할 수 있다. 다른 상황에서 Store C를 기다려야 할 수도 있다. waitFor() 메소드에 코드 블럭을 활용해 특정 action에만 동작하도록 만들 수 있어서 의존성에 대한 미세한 조절이 가능하다.
그러나 순환 의존은 문제가 발생한다. Store A가 Store B를 기다리고 그 반대로 Store B도 Store A를 기다린다면 무한 순환에 빠지게 된다. Flux의 dispatcher는 이제 이런 경우를 보호하기 위해 유용한 에러를 던지고 사용자에게 문제가 발생하였다고 알릴 수 있게 지원한다. 개발자는 세번째 store를 만들고 순환 참조를 해결하도록 만들 수 있게 되었다.